
Using DRM to control access to websites and webpages
Protect IP

Secure PDF documents without useless passwords:
- Stop unauthorized access
- Stop sharing and distribution
- Strong US Gov strength encryption, DRM and licensing controls
Restrict Use

Set Expiry

Revoke Access

Watermark

Log Use

Comply Law

Benefits

 Free Trial & Demo
Free Trial & Demo
Trusted by:
 What is web access control?
What is web access control?
 What is web access control?
What is web access control?
Webpage access control is the mechanism by which access to web pages is limited to specific users.
Web page access control may be achieved in a number of ways and fundamentally comes down to the authorization vs authentication discussion. Webpages typically authenticate users with simple username and password access control, the problems of which we have discussed at length in web page login and web login.
 Web access control and login security
Web access control and login security
 Web access control and login security
Web access control and login security
One way solutions add additional sophistication to their access controls is through additional authentication that a user is who they say they are. The methods employed here can vary in complexity from proving you are human using Captcha to confirming that you are part of a specific employee group authorized to access the content (RBAC). However, all of the techniques used mitigate the risk of unauthorized access rather than eliminating it:
- AI can beat Captchas 100% of the time. It’s better at pretending to be human than a human is. As a result, while Captcha slows down automated login attempts, it doesn’t eliminate them completely.
- Attackers can bypass IP whitelisting using a VPN or proxy. This can be achieved by renting an IP block from the same ISP or cloud provider, or through inside help/a compromised device.
- MFA, OAuth, and SSO primarily protect against non-targeted, outside threats. A malicious or compromised internal actor can still provide their MFA code/SSO login/OAuth to somebody else, whether intentionally or by phishing. Attackers may also use non-login-based attacks, such as session hijacking, which allows them to log in without credentials.
- Role-based access control (RBAC) is unwieldy to implement and doesn’t enforce many controls itself. It primarily relies on the security of whichever application you’re using. While it does do API checks, these can often be bypassed by modifying URLs, the HTML page, or using a custom API attack tool.
- Client Certificates can often be stored or shared. Unless they are encrypted and locked to devices, attackers can gain access to legitimate users’ certificates and their associated private keys via malware, phishing, social engineering, etc. Some systems also show issues with certificate validation, are vulnerable to man-in-the-middle attacks (via a trusted device), or fall back to a weaker form of authentication when unavailable.
All of this, however, ignores a fundamental part of the equation: what happens after an authorized user gains access to the content? How do you ensure that authorized users do not share or misuse it? Most likely, it will utilize some form of encryption.
Web access control and encryption
 Web access control and encryption
Web access control and encryption
There are two levels of security when applying encryption in order to provide web page access control. At the simplest level, the encryption key is either a password that the user enters or a password that is carried in the page itself and is used dynamically to decrypt the underlying information and pass it into the web browser.
This first method has two obvious problems. If a user can enter a password, then the page can be attacked easily by a hacker using a dictionary attack. This involves trying hundreds of different combinations per second until the correct password is found. Since passwords tend to be short and memorable, this approach is usually effective. Additionally, the key is sometimes found somewhere in the HTML code of the page. In this case, it’s not going to take someone long to build a tool to automatically find the key and apply it in order to decrypt the page information. If you do a web search for “HTML decrypter”, you should get around 15 million results.
As a result, at the more complex level, you need an application to handle the access to the decryption key(s) and a special viewer to ensure that neither the content nor the underlying information can be accessed by the user, even when they can see the information they require on the screen. This also ensures that locating and using the relevant decryption key is not simple for an attacker. They instead need to make use of an exhaustive key attack (start with the value of 1, add 1, and keep going until you find it), which is impractical. A strong enough key, and you could be looking at a billion years before current computers can crack it.
A different approach might be to use the system proposed in the OASIS SAML specification, but we have pointed out in our article on web login that the implementation of such an approach is so challenging that there are no useful examples to point to. I might be accurate to say that it seems to be a technology solution for technologists who have so far found nothing that it really maps to.
To summarize, web page access control is best achieved by using an encryption technology, but you require something better than the trivial encryption methods if you are going to achieve any realistic security.
Safeguard PDF Encryption Software: securely encrypt PDF files without passwords
How to encrypt a PDF without Passwords
Encrypting a PDF or multiple PDF files is simple and secure with Safeguard PDF Security.
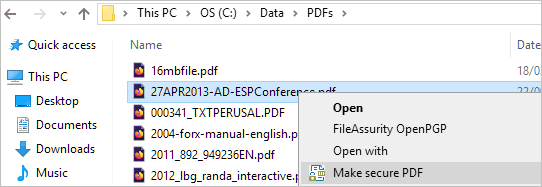
To encrypt PDF files, right-click on them in Windows File Explorer and select the menu option ‘Make Secure PDF’.
Strong PDF Encryption with DRM controls
Safeguard PDF security takes PDF encryption to the next security level. It encrypts PDFs with US Gov strength AES encryption to prevent unauthorized access, and applies DRM to control what authorized users can do with your PDF files:
- stop sharing
- stop copying
- stop editing and modifying
- stop or limit printing
- stop screen shots
- control expiry (how long your PDFs can be used for)
- revoke access at any stage
- add dynamic watermarks to identify users
- lock PDFs to country and IP locations
- track document use
Safeguard provides strong PDF encryption with total document control:
- PDFs are locked to individual devices
- content is only ever decrypted in memory
- there are no passwords to enter or manage, or for users to share or forget

Customer Testimonials















