revoke individual user access to single, multiple, or all documents
revoke access automatically after a number of views and/or prints
Watermark
Add dynamic watermarks to viewed and or printed pages. Dynamic variables (date/time, user name, company name, email address) are replaced with actual user and system data when the protected PDF document is displayed and/or printed.
You only have to protect a document once in order to customize it for multiple users.
see what devices & operating systems users are using
Comply Law
Comply with legislation by controlling access and use:
Ensure only authorized parties can view confidential documents
Enforce document retention policies with automatic expiry
Log use for proof of when documents are viewed and printed
Benefits
Protect IPR, reduce costs, ensure compliance, gain new revenue:
Protect revenue and increase ROI – reduce losses and costs
Take control over your IPR, prevent document leakage & theft
No cost per document or user – one fixed price for unlimited use
Free Trial & Demo
“Fantastic product… outstanding support.”
“We would recommend Locklizard to others”
“The clear leader for PDF DRM protection”
“Our ebook sales have gone through the roof”
“Simple & secure – protects IPR from theft”
Trusted by:
Using Locklizard to Protect & Distribute PDF files securely without passwords
Strong PDF Encryption with DRM controls
Safeguard PDF security protects PDFs with US Gov strength AES encryption to prevent unauthorized access, and uses licensing and DRM to control what authorized users can do with your documents:
PDFs are locked to individual devices so they cannot be shared
there are no passwords to enter, manage, share, remove or forget
How to distribute a PDF document securely
Protecting and distributing a PDF or multiple PDF files is simple and secure with Safeguard PDF Security.
Admins protect a PDF file using Safeguard Writer and then add their intended recipients as users in their admin portal. The system will automatically send them an email with the license file and a link to the Safeguard Reader application required to open the document. The protected document can then be delivered however you like, as only authorized users can open it.
Here’s how to distribute a document securely:
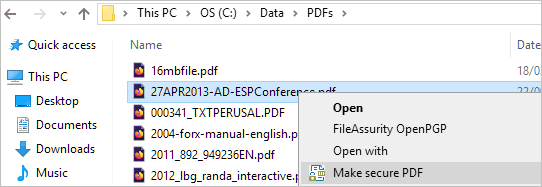
To protect PDF files, right-click on a PDF on your desktop and select ‘Make Secure PDF’.
Creating a protected PDF file
Select the copy protection controls you want to apply. By default, editing, copying, and printing are disabled.
Encrypting a PDF without passwords using Safeguard PDF DRM
Press the Publish button to protect the PDF document.
Distribute your protected PDF document just like any other file – email it, let users download it from your web site or file sharing system, or share a PDF link securely. It does not matter who downloads your protected PDF files (.PDC files) as only those authorized will be able to view them.
Why encryption and passwords is not enough to securely distribute documents and PDF files
Encryption protects against unauthorized access, not document use
Users can share passwords, and therefore ‘protected’ documents
Once a document is decrypted, users can do what they like with it
You need licensing controls to lock documents to authorized devices
Only DRM can control document use (copy, print, screengrab, etc.)
“We purchased Safeguard PDF Security to securely distribute PDF files, control document access and un-authorised use.
We now have greater control on who/how our material is accessed when distributed around the world, including limiting the number of prints and using expiry controls to manage subscriptions.
We would recommend Locklizard to other companies for secure PDF distribution.
To prevent users from sharing protected documents with others, Locklizard locks document use to authorized desktop or mobile devices.
If an authorized user forwards a protected document to another user, they will not be able to open it unless you have authorized that device.
Lock documents to locations
There may be occasions when you do not want confidential documents to leave your office premises – internal document distribution means just that. But with BYOD (bring your own device), this has become a difficult problem to solve.
Locklizard document security lets you lock PDFs to specific locations (say an office) so that your confidential documents will only be viewable from that location and no other.
Location locking can be enabled on a global or user basis and at both country and IP levels.
Expire Documents
Locklizard enables you to enforce document expiry either on a given date or following document usage rules.
There are many reasons you may want to expire PDF documents when securely distributing documents:
to comply with document retention policies
to enforce version control
free trial usage (e.g. 1 or 2 views before purchase)
enforcing complying with disclosure requirements
enforcing subscription periods to a service or series of documents
Expire PDF files:
After a number of views
After a number of days
On a fixed date
After a number of prints
When a subscription period has ended
At any time you decide
Set documents to automatically expire on a document and/or user basis (so the same document will expire at different times for different users).
Revoke document access
Being able to revoke document access can be vital when confidential documents have been distributed or where chargebacks have been applied against a purchase of a document (e.g. a book, a report or a training course).
Locklizard enables you to revoke PDF files at any time regardless of where they are located, ensuring your documents are always under your control.
Track document use
Tracking if or when a protected document has been opened or printed can be essential for accountability or audit purposes. You may need to prove that the recipient has not only received the document but has also read and/or printed it.
LockLizard enables you to track and monitor PDF use by recording all document opens and prints. See the number of times each document has been opened and printed, when and where this occurred and by whom.
Permanent & Dynamic watermarks
Quickly add custom “not for distribution” watermarks to all copies of your PDF. Use dynamic variables that are replaced with user information on print or open to dissuade unauthorized sharing.
Managing secure distribution of confidential documents & PDF files: DRM in content life cycle
Defining content lifecycle
Content lifecycle is defined by some as the series of changes in the life of any piece of content, including reproduction, from creation onward. This definition is somewhat inadequate in regards to confidentiality, as a document’s classification may vary regardless of changes to the document itself. The apparent importance of content may change due to additions in a wider collection of content or changes to the perception of the value/importance/secrecy of certain content.
For instance, a person’s name without any other data is not confidential, but if it is connected to their medical records it certainly is and should be protected in line with HIPAA requirements. Or, customer political information may not have been considered sensitive personal data until GDPR came into effect.
Who is responsible for defining what content is confidential & secure document distribution?
Managing secure document distribution for confidential or sensitive documents (use of Digital Rights Management) is a dynamic activity. There have been many attempts to automatically determine when documents are confidential (some by text examination and others by analyzing metadata), but these have all had their problems because even experts can find classification difficult. The word ‘acquisition’ for example, may be confidential in the context of buying a corporation but uninteresting when buying a software package. Linguistic context may not help – “This will be an important acquisition,” does not tell us much unless a monetary sum is conveniently nearby.
Generally, when sensitive information or confidential documents are to be distributed, it is known at a management level if the content should be controlled or not. Responsibility for managing the situation is typically down to either IT systems managers, where the distribution is from computer application to computer application, or departmental management, where the document distribution happens.
Is the content confidential?
Though some organizations may develop a set of guidelines, there is no binary definition of confidentiality. It’s useful to think not of the content itself, but of the impact that content would have should it become public knowledge.
Let’s take the disclosures of Edward Snowden in 2013 as a high-profile example. One of the leaked documents, a PowerPoint updating parties on the companies who have data sharing agreements, probably wasn’t that interesting to anybody at the NSA. However, this document, and documents like it, ultimately led to the invalidation of the EU-US Safe Harbor Agreement and caused overwhelmingly negative press for both the NSA and the tech companies involved.
The same can be applied on a far less drastic scale. The leak of a common customer name, say, “John Smith”, probably won’t be damaging. But if that customer’s name is something uncommon, say “Elon Musk”, or is accompanied by a date of birth, suddenly that information is identifiable.
So, the answer to whether or not content is confidential will depend on whether somebody has deemed the damage its leak would cause significant enough for it to be classified as such. Either way, had DRM-enforcing technologies been in use by the NSA, the press would have received nothing from Snowden other than a near-useless, encrypted jumble. Protect the file’s content, and the only information that can be shared is its file name and other metadata. If you can also remove metadata from the PDF that can identify users before publishing – even better.
Distributing documents securely and the role of encryption
Exchanges between computer-based applications generally use encryption in order to protect the transfer from being intercepted or misused. But managing the document content itself has proven rather more difficult. Trying to use encryption on its own is technically difficult because although it perfectly preserves the original content, it has no continuing control over how a file is used once it is decrypted and returned to its original form.
A simpler approach to exerting continuing content control has emerged with the increasing availability of Digital Rights Management technologies that can be applied to important documents in order to protect confidential content. This works because using DRM it is possible to control subsequent use of the document instead of relying upon ‘conventions’ or ‘understandings’ as to how the content is to be controlled once it has been disclosed.
Confidentiality through redaction
A commonly used alternative, although rather less successful in the world of digital documents, is the use of data redaction to control access to sensitive information.
Data redaction is used to render only specific data items inaccessible, and it does not seek to control the subsequent use of the sensitive documents’ content. It does so by blanking over the part of the document that is confidential, but leaving the surrounding information untouched. In many systems, this is achieved by putting a mask over the visible content without removing the underlying content. This is problematic because the underlying data remains accessible to anyone able to edit the file or view its code. Thus, an unauthorized user can read and process the unredacted text.
A redacted document in Safeguard PDF viewer
Adding confidential watermarks
While many applications (Adobe, MS Office, Google Docs, etc.) can be used to easily add a confidential watermark to a PDF, they all suffer from the same problem – namely it is trivial to remove them. Users can instantly remove restrictions and then edit the document to remove all watermarks in a single action.
DRM is used to prevent users editing PDF content and stop screenshots being readily taken, so that watermarks cannot be easily removed.
Content available for a limited time
According to James Bond, “Diamonds are forever,” but the same certainly isn’t true for document content. Frequently, controlled content has limited accessibility. This may be due to information being superseded and so is no longer valid, or that it is only given a certain lifetime to begin with. Controls are needed to prevent this content from being available before it is officially released or after it has reached the end of its lifecycle.
Overall, document distribution software needs to take into account a number of dates:
the date before which the content may not be used
the length of time the content can be used for (some legislatures mandate 6 years maximum from collection to use personal information); the date on which the content ceases to be available, or on which it becomes publicly available
the length of time content can be used after first being used
the number of times that the content may be used by a specific user.
Document expiry should happen automatically whether the user is online or offline, with the ability to also revoke access manually when the need occurs.
Content kept confidential by location
Further content controls may be applied at the IP address level. At one level, this kind of content control is used to prevent data leakage outside of specific networks or groups of networks. Either all documents are restricted to one or more individual or groups of network addresses, or specific users are restricted to the range of acceptable addresses they can use content that is protected.
Using IP level controls may also be extended to determining the geographic locations that are permitted. This may prove to be an essential technique when some documents may be embargoed in some countries, or where content is country specific. For instance French content may be restricted to France and Canada and not available in Belgium, where English content may be provided. Also, some countries may forbid or censor content and prosecute publishers who fail to prevent content use when it is not approved.
Auditing use of confidential content
Underpinning content control is providing audit information about the use of content. It is all well and good having applied content controls, but how do you know they are working? Where content is being used, logs need to be maintained that list which users have opened the documents, at what time, and from what IP. This may also enable content controllers to identify if sensitive data is being accessed in locations that are inconsistent (appearing in a country they are not expected to be in, for instance, or being in several places at the same time) and might require investigation.
Summary: Secure document distribution and content management
In summary, secure document distribution and content management for confidential documents may be achieved by using DRM security features. These enable you to bind controls to the content that are abiding. Confidential content in a lifecycle management sense has many dimensions beyond file access controls: Controls are needed by dates, numbers of accesses, numbers of printed copies made, and location in order to allow the content owner to be effective in managing confidentiality. Further, there must be provisions for the content owner to change their minds about controls such as start and expiry dates and prints.
FAQs
Is secure document distribution with Google Drive feasible?
Additionally, it’s just not a good idea to upload unencrypted sensitive documents to the internet. If Google’s server gets hacked due to a security breach or a rogue employee decides to steal some data, it’s your business on the line.
Is it possible to distribute documents securely via email?
Yes, absolutely. The documents just need to be protected with a DRM solution before you attach them. The problem with email services is that they only offer end-to-end encryption of device attachments at best. This does nothing to stop the receiver from sharing it with anyone they wish once they have decrypted it.
Are secure file sharing services or a secure portal a replacement for DRM?
Secure file sharing services are generally just regular cloud file storage services with end-to-end encryption and two-factor authentication tacked on. Occasionally they do include expiry controls, but these are ineffective as browser-based solutions can’t stop someone from copying the content to another document and keeping it past the expiry date. See is FileCloud Safe? as an example of limited DRM restrictions.
If you want to control what happens to the document after it has been opened, then DRM is usually the best choice.
Is a secure link effective for distributing files securely?
No, once a user has downloaded the file they can share it with others without any restrictions, (expiry controls only apply to the link). Dropbox for example lets you password protect files or a folder and then share a link to them, but once someone downloads them they can be easily shared without any protections.
Is password protection enough to protect business documents during distribution?
Ultimately, password-based encryption isn’t enough to protect the document when it is in use. For that, you’ll need a DRM solution.
Is Microsoft Word password protection useful for secure document distribution?
No, it is no better than any other form of password protection – authorized users can remove the password or just share it with others. Also, Word watermarks and document restrictions can be easily removed, so there is no additional benefit in using Word to password-protect docs.
Does Locklizard document DRM integrate with our existing workflow?
Yes, you protect PDFs on your PC and distribute a Locklizard protected document just like any other file. Document protection and Admin System functionality (like assigning document access) can be automated for hassle free integration.
Does Locklizard help my business comply with HIPAA, GDPR, FINRA, and other regulations?
Yes, Locklizard ensures your documents can be securely distributed and used in a controlled manner. You can automatically cease access after a certain time period, manually revoke access and track use. Locklizard uses cryptography and licensing controls to ensure your documents can only be accessed and used by authorized users. Take a free trial to see how your business can benefit.
How do you protect your PDF from distribution?
You have to use PDF DRM protection since password protected PDF files can be shared with others and restrictions easily removed.
Customer Testimonials
We needed to deliver e-book versions of our handbooks while not compromising on security and digital rights. Safeguard PDF security is easy to use and intuitive.
The implementation was painless and we now have a greener, more secure way of distributing training manuals.
Locklizard’s PDF protection is exactly as described – the features are highly effective and I would give it 5 stars.
I would recommend Locklizard to others - their security is simple to use and fit for purpose. It meets common needs of businesses who have information they want to protect.
We would be happy to recommend Locklizard to any company needing a flexible way to secure PDF files.
Safeguard PDF Security has provided us with a very workable solution for sharing of information in a secure fashion. The support has been excellent and very accommodating.
We can cut accounts for a user five minutes before his class starts and he is ready to go. Happy smiling customer, while we still have security and personalized watermarking.
I have immense respect for the product and Locklizard provide great customer satisfaction and service.
We would recommend Safeguard to other companies for its security, cost and ease of use. It does what we expected it to do and more.
Ease of use is a bonus and the implementation was very easy. The product manual is excellent and Locklizard staff are very accommodating.
We sell a highly valued educational product in an open and competitive market so it was important to ensure we had effective security to protect our digital rights.
We highly recommend Locklizard - a professional company with a competitive and professional PDF Security product.
We would absolutely recommend both Locklizard as a company, and Safeguard PDF Security. It has transformed our study materials to the next level.
Not only did this increase sales, but we also believe that it has increased our customers’ ability to learn, which is even more important!
We would recommend Locklizard Safeguard to other companies that need to protect PDF reports. Customers have found the process of accessing the protected documents to be seamless.
Implementation was easy and technical support has been very responsive to requests for help.
Our company would without reservation recommend Locklizard. Their document DRM software opens up delivery of our new products in a timely fashion while knowing that the content will remain secure.
The return on investment to our company has been immediately evident.
We use Safeguard to make sure that documents cannot be opened outside our local network or from a unauthorized computer in order to copy or print the documents.
It is the most feature rich, affordable, & simple to use PDF security product on the market.
Safeguard PDF Security is simple to administer and meets our needs, consistently delivering secured manuals to our customers with ease.
Return on investment has been elimination of many man hours, printing resources and postage – it is estimated that costs decreased by 50% or more.
We would really recommend Safeguard PDF Security to every publishing company for managing ePubs or e-books securely. It is easy to secure PDF files and simple to distribute them to our authorized customers only.
Locklizard also provides a good customer support experience.
The ROI for us is incalculable. We have the security of knowing that our proprietary documents are secure. This is the entire value of our company.
I would most certainly recommend your PDF security product and already have. The ease of implementation was surprising.
We can now sell our manuals without the need to print them first, saving time, money and helping safeguard the environment.
We would recommend Safeguard PDF DRM – it is the perfect solution to sell and send e-documents securely whilst making sure someone cannot copy them.
We would recommend Locklizard to other companies without hesitation.
Their PDF DRM products provide a manageable, cost effective way to protect intellectual investment and they are always looking for ways to improve them. Moreover, their staff provide an excellent level of support.








 Free Trial & Demo
Free Trial & Demo




 SECURE DOCUMENT DISTRIBUTION
SECURE DOCUMENT DISTRIBUTION


 Defining content lifecycle
Defining content lifecycle Who is responsible for defining what content is confidential & secure document distribution?
Who is responsible for defining what content is confidential & secure document distribution?
 Distributing documents securely and the role of encryption
Distributing documents securely and the role of encryption
 Confidentiality through redaction
Confidentiality through redaction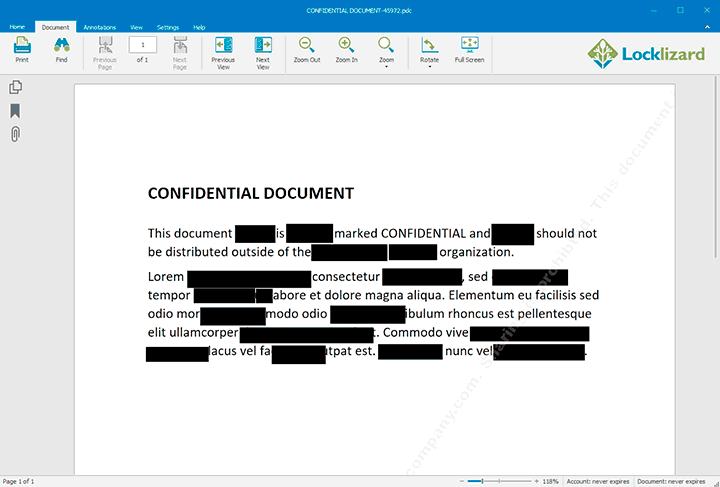
 Adding confidential watermarks
Adding confidential watermarks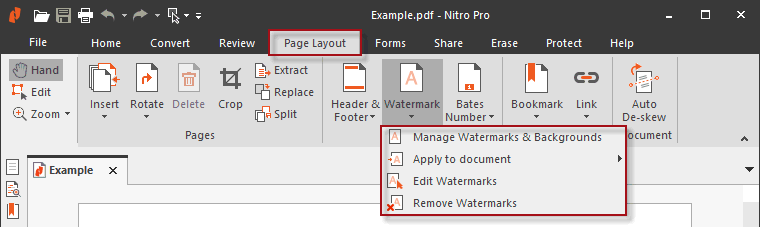
 Content available for a limited time
Content available for a limited time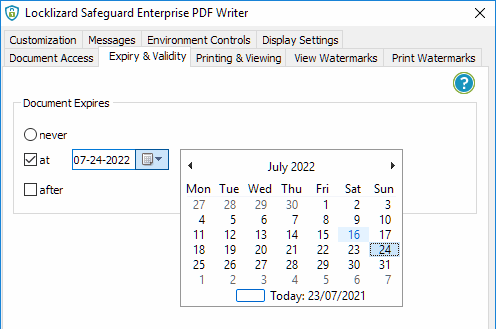
 Content kept confidential by location
Content kept confidential by location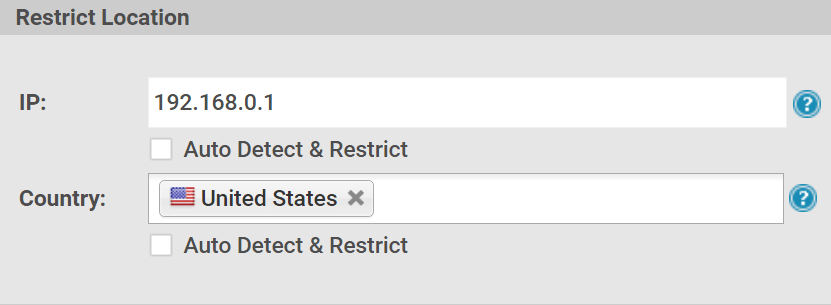
 Auditing use of confidential content
Auditing use of confidential content
 FAQs
FAQs















